Architecture for a buck
| « The importance of terminology | Details: OneWire bus enumeration » |
My primary architectural goal for this system was simplicity, followed by cost. After all it's a completely needless side project and I didn't want to spend any real money on it.
My target cost was order-of-magnitude a buck a month, and we're doing pretty well: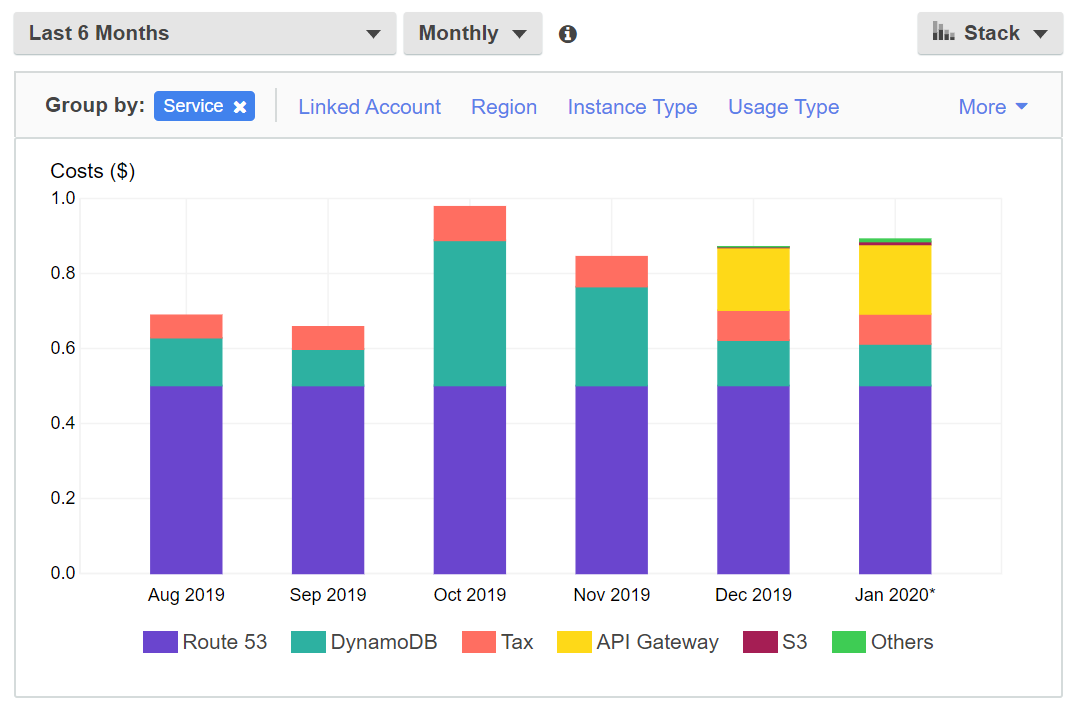
It's pretty miraculous what you can do with high-level PaaS cloud-hosted services that bill by use and have a pretty high free tier. At this point I cut could my costs in half by hosting my DNS elsewhere; I'm just using Route53 for ease of deployment since I automate DNS in my CI/CD.
You had one job
Well, maybe three.
At its core, WarmAndFuzzy is a simple CRUD system with minor extras:
- There's system configuration that devices need to be able to access and users need to be able to edit
- Devices need to report status that users can view
- Devices' timeseries history needs to be recorded and offered up for analysis and exploration
So it's basically a my first IoT system starter pack. And of course there's firmware too.
Be boring
In order to achieve my goals for simplicity, I turned to what struck me as the sweet spot of advanced but boring technology: Advanced enough that a piece of tech could cover as many needs as possible at a time, and boring enough that I wasn't dogfooding some new craziness with zero answers on StackOverflow.
- Advanced but boring languages
- All non-device code (frontend, backend, tooling) is TypeScript
- All on-device code (firmware) is C++
- All cloud goop is platform-as-a-service - no VMs, no containers
- All code runs as AWS Lambda
- All data lives in AWS DynamoDB
- All frontend code is React/ReactNative
- State is managed in MobX stores (no Redux, reducers, etc.)
- Advanced but boring engineering practices
- All infrastructure is defined in code using the Serverless framework
- All code and infra is built in CircleCI
- All code lives in a single monorepo
- All code is auto-styled and -formatted
- Authentication with Auth0
- Because AWS Cognito is unusable and every other auth provider is worse
Everything is as stateless as possible. For example:
- The cloud doesn't know what configuration and settings each device has retained; it just always sends down the latest whenever a device sends up an update. (We're on WiFi, not 3G or LoRaWan, so that's okay enough.)
- The cloud always sends the full schedule of settings to each thermostat, giving the thermostat full control over evaluating the settings bundle against current time and location.
- Any display of what a thermostat is currently up to is based on status reported back from thermostats. There is only one piece of code that evaluates a settings schedule and that's in the firmware.
- State is only kept in the database. All cloud code is stateless.
Any state is centralized:
- The cloud is the only source of truth for thermostat settings and configuration and is treated as read-only by the thermostats.
- Any change to thermostat settings and configuration needs to route through the cloud.
- Thermostats have no local control affordances.
- Thermostats expose no API over the local network.
This means that if our internet goes out, you can't update the thermostats' settings. On the other hand, as long as there's still power and the real-time clock of the thermostats isn't shot, they'll continue to faithfully execute their schedules and/or expire previously set holds (they do buffer their desired state in EEPROM).
This wasn't as popular a decision with the residents of the house as it was with my inner software architecture nerd, but it's made the system far easier than it might have otherwise been, and if all else fails, we can always blam a physical jumper into the control panel for the system.
Particle in the middle
Recall that Particle is the manufacturer I chose for the system-on-chip platform in the thermostats because their platform includes firmware-as-a-service management services as well as a device cloud that connects devices to webhooks. (The price point for their service at my scale is hard to argue with: it's free.)
One thing their platform is surprisingly bad at (compared to e.g. Balena) is secrets management: there is no way for me to configure a per-device secret that the firmware can use to authenticate to an API of my choosing.
I'd have preferred an MQTT-based approach, but without proper secrets management this was going to end poorly. Instead I have to rely on the Particle cloud to connect my devices to webhooks (because vendor lock-in is dope) so that's the one piece of complexity I just wasn't able to cut out. The Particle webhook configuration is where I get to specify the API key secret that Particle's cloud uses to talk to my API.
That said, the webhook-based approach has worked out just fine and I'm somewhat glad that I didn't need to take on the full burden of MQTT.
Firmware
The firmware lives in the firmware package of the repo and is pretty basic.
Every so often (as configured through its cadence) the device wakes up, samples its sensors, reflects on its settings to figure out what the current actions should be, and sends a record of that to the cloud, receiving the latest configuration and settings in response.
When compared with the insanity of TypeScript, heap space is precious on the Particle Photon (32KB) and stack space even more so (5KB/thread). With the small amount of heap space, fragmentation becomes a concern so small stuff should really go on the stack, but larger stuff is too large to go on the stack so those should become fixed-size heap allocations. None of this is difficult or revolutionary, but it's quite the brain melter to go back-and-forth between TypeScript running on many-GB VMs and then count bytes in C++.
(For extra credit, ARM is an alignment-faulting architecture and the Particle OS doesn't do fixups, so that's another fun thing to consider when tweaking bytes out of structures.)
A few notable pieces of code that came in handy:
- I wrote an Activity class that's a RAII object to track activity timing and labeling. It's been a wonderful debugging tool. It looks eerily like Win32's
TraceLoggingActivitybecause it seems that when I find one concept useful, I just can't stop replicating it. - I wrote an entire OneWire stack to collect temperature readings from external sensors. All the OneWire code I could find relied on bit-banging GPIO ports and I'm using an I2C-based DS2484 as my bus controller since bit-banging a 6'/ten-device-long OneWire from GPIO just doesn't work well. The most fun part of this ended up being the bus enumeration code.
The API
The cloud side of things (a.k.a. The API) lives in the API package of the repo.
serverless.yml defines all the infrastructure, consisting of:
- A bunch of DynamoDB tables that directly map to the concepts outlined in the post on terminology.
- An authorizer lambda that protects the GraphQL and REST endpoints
- A single GraphQL endpoint for everything the frontends use, built on Apollo's GraphQL server which is pretty trivial to instantiate inside a Lambda.
- A trivial REST endpoint I use for backing up system configuration with Postman in the rare case that I need to flatten the infra
- A webhook that is invoked by Particle when a device reports in
- A DynamoDB stream handler (not to be confused with my use of the term stream) that is invoked whenever thermostat settings or configuration are updated; it then pushes those changes down to the given device so that people don't need to wait ten minutes for requested changes to take hold.
Shared code
There's a shared package for code shared between the API and frontends, and a shared-client package for code shared just between the mobile and web frontends.
The shared package provides yup-based schema definitions for every GraphQL type to provide more fine-grained definitions (e.g. value ranges). These are used by the frontend to validate form values before sending them across the wire, and by API code to validate any requested mutations.
In an ideal world I'd like articulate these as custom GraphQL directives and then extend the GraphQL code generator to emit a yup schema, but it wasn't a hill I felt like dying on. yup is awesome, by the by, though questions of nullability/optionality are as convoluted as they ever are in JavaScript.
The shared package also shares non-secret auth configuration data.
The shared-client package provides shared data stores, unit-of-measurement management, and auth management services.
Frontends
The mobile and web frontends are written in ReactNative and React, respectively.
The capabilities of both frontends are identical for normal users (e.g. inspecting system status, changing thermostat settings, ...), though administration (e.g. thermostat configuration) and data exploration is only in the web app.
The amount of code sharing (c.f. above) has been fantastic. Pretty much everything one would consider "business logic" in the old days is shared between the frontends.
Data and auth state is managed using MobX, which has been an absolute pleasure to work with. Separating data from React's state tree has allowed me to minimize app-specific code.
| « The importance of terminology | Details: OneWire bus enumeration » |